Introduction:
A decision tree is a flow-chart-like tree structure:
問題: 建構決策樹時,該優先選擇那個屬性來進行「分支」的動作?
Entropy 熵:亂度、隨機程度
考慮以下三個機率分佈函數:
那一個「比較隨機」? 第一個並沒有隨機性,「亂度」應最小 ; 第三個隨機性應最高,「亂度」應最大! 那怎樣估算一個機率函數的「混亂程度」?
Entropy: Definition

Entropy 可被用來估算隨機變數在機率分佈上「有多隨機」。熵值越高,表示該隨機變數的「混亂程度」越大。 另外一種解釋,是將 Entropy 視為該隨機變數在隨機試驗前的不確定程度。因試驗後結果確知(亂度或不確定性減少),我們說該試驗提供了試驗前 Entropy 值(單位為 bit)那麼多的資訊量!
Entropy: Illustration
對先前提到的三個機率函數而言, 其 entropy 為:

Branching: Idea
回到之前決策樹選擇屬性進行測試的想法:確定某個屬性之後,亂度 (entropy) 應減少. 測試每個屬性確立後所能獲得的資訊量。將「分支前的總亂度」減去「分支後的總亂度」,就是該屬性所能獲得的 information gain!

Building a Decision Tree:
我們利用 information gain 來選擇用來進行分支的屬性:
尚未進行 branching 前,樣本空間的亂度是:

其中 pi 是該樣本空間中,類別 Ci 所佔的比例(或者說,任取一個樣本,它會屬於 Ci 的機率)
若 training set 為一個良好的取樣,則可利用 training set 的統計值,作為「分支前樣本空間」統計量的估計值。 也就是說,我們可用 si/S 來估算 pi,或者用 S 來分析 X 的特性. 若屬性 A 有 v 種可能結果 {a1, a2, ..., av},則我們可用該屬性來將 S 分割為 v 個子集 {S1, S2, ..., Sv},其中 Sj 是 S 中屬性 A 的值為 aj 的集合。
令 sij 代表在 Sj 中,屬於 class Ci 的樣本數量。 則利用屬性 A 將 S 分支後的總熵值(分支後的系統亂度)為:

因此,利用屬性 A 進行 branching,其 information gain 為:

對每個屬性計算「利用該屬性進行分支」所能產生的 IG。選擇能夠得到最大 IG 的屬性來進行 branching! 持續進行 branching 的動作,直到不能再分支為止.
Decision-Tree Algorithm:

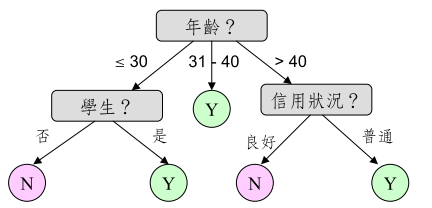
Example: Test Attribute Selection

14 個 training data 中,有 9 個 YES,5 個 NO。因此其 Entropy 為:

接著假設挑選 「年齡」作為測試屬性, 計算 entropy for attribute「年齡」:

同樣地,計算「收入」、「學生」、「信用狀況」得到: IG(收入) = 0.029,IG(學生) = 0.151,IG(信用狀況) = 0.048 .因此,選擇「年齡」這個屬性來進行第一層分類!

Toolkit 使用:
根據上面的說明, 我實作了該演算法為 "DTBuilder.groovy". 有興趣可以下載來自己研究, 至於使用的方法可以參考下面範例代碼:
- def labels = ["Age", "Income", "Student?", "CC", "Class"]
- def datas = [["<=30", "高", "N", "O", "N"],
- ["<=30", "高", "N", "G", "N"],
- ["31-40", "高", "N", "O", "Y"],
- [">40", "中", "N", "O", "Y"],
- [">40", "低", "Y", "O", "Y"],
- [">40", "低", "Y", "G", "N"],
- ["31-40", "低", "Y", "G", "Y"],
- ["<=30", "中", "N", "O", "N"],
- ["<=30", "低", "Y", "O", "Y"],
- [">40", "中", "Y", "O", "Y"],
- ["<=30", "中", "Y", "G", "Y"],
- ["31-40", "中", "N", "G", "Y"],
- ["31-40", "高", "Y", "O", "Y"],
- [">40", "中", "N", "G", "N"]]
- // Part1
- DTBuilder dtb = new DTBuilder(dataSet:datas, labels:labels)
- def ageSet = [] as Set
- def incSet = [] as Set
- def issSet = [] as Set
- def iccSet = [] as Set
- ageSet.addAll(datas.collect {it[0]})
- incSet.addAll(datas.collect {it[1]})
- issSet.addAll(datas.collect {it[2]})
- iccSet.addAll(datas.collect {it[3]})
- def origE = dtb.calcShannonEnt(datas)
- printf "\t[Info] Original E=%.03f\n", origE
- printf "\t[Info] Calculage Age E:\n"
- double aftrE=0
- for(age in ageSet)
- {
- def sd = dtb.splitDataSet(datas, 0, age)
- def se = dtb.calcShannonEnt(sd)
- printf "\t\tAge='%s' with E=%.03f\n", age, se
- aftrE+=(((double)sd.size())/datas.size())*se
- }
- printf "\t[Info] IG(age)=%.04f!\n\n", origE - aftrE
- printf "\t[Info] Calculage Income E:\n"
- aftrE=0
- for(inc in incSet)
- {
- def sd = dtb.splitDataSet(datas, 1, inc)
- def se = dtb.calcShannonEnt(sd)
- printf "\t\tIncome='%s' with E=%.03f\n", inc, se
- aftrE+=(((double)sd.size())/datas.size())*se
- }
- printf "\t[Info] IG(Income)=%.04f!\n\n", origE - aftrE
- printf "\t[Info] Calculage Student? E:\n"
- aftrE=0
- for(i in issSet)
- {
- def sd = dtb.splitDataSet(datas, 2, i)
- def se = dtb.calcShannonEnt(sd)
- printf "\t\tissSet='%s' with E=%.03f\n", i, se
- aftrE+=(((double)sd.size())/datas.size())*se
- }
- printf "\t[Info] IG(Student?)=%.04f!\n\n", origE - aftrE
- printf "\t[Info] Calculage CC E:\n"
- aftrE=0
- for(i in iccSet)
- {
- def sd = dtb.splitDataSet(datas, 3, i)
- def se = dtb.calcShannonEnt(sd)
- printf "\t\tissSet='%s' with E=%.03f\n", i, se
- aftrE+=(((double)sd.size())/datas.size())*se
- }
- printf "\t[Info] IG(CC)=%.04f!\n\n", origE - aftrE
- // Part2
- def decisionTree = dtb.createTree()
- printf "\t[Info] Decision Tree: %s\n\n", decisionTree

Supplement:
* [ ML In Action ] Decision Tree Construction

沒有留言:
張貼留言